Consistent Hashing 广泛运用于动态变化的Cache系统中
基本场景
假设 $N$ 台 ${cache}$ 服务器,现需将任一对象 $object$ 映射到 $N$ 台 ${cache}$ 中的一个。通常做法是计算 $object$ 的 $hash$ 值,然后均匀的映射到 $N$ 台 ${cache}$ 中。计算方法: $hash(object)\%N$ 。
情景1: 某 $cache_m$ down 掉了,这样映射到 $cache_m$ 的对象都会失效,需要把 $cache_m$ 从 ${cache}$ 中移除,这样 ${cache}$ 集合就缩减为 $N-1$ 台,计算公式变为:$hash(object)\%(N-1)$。
情景2: 由于访问量激增,现有服务器不能满足需求,需要增加新 $cache$,这时候 ${cache}$ 集合增加为 $N+1$ 台,计算公式变为:$hash(object)\%(N+1)$
情景3: 对于硬件能力较强的 $cache$,希望能多承载点负载。
以上情景1和2,意味着几乎所有的cache都失效了,对服务器而言,类似洪水般的灾难。
Hash算法和单调性
Hash算法的一个衡量指标是单调性(Monotonicity),定义如下:
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
此外还有三个评测哈希算法好坏的指标:
平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
分散性(Spread):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
Consistent Hashing算法的原理
Consistent Hashing 是一种哈希算法,在移除 / 添加一个 cache 时,它能够尽可能小的改变已存在 key 映射关系,尽可能的满足单调性的要求。其基本原理如下:
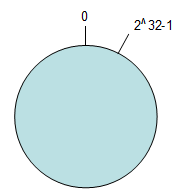
1. 环形Hash空间
按照常用的hash算法来将对应的key哈希到一个具有2^32次方个桶的空间中,即0~(2^32)-1的数字空间中。现在我们可以将这些数字头尾相连,想象成一个闭合的环形。如下图:
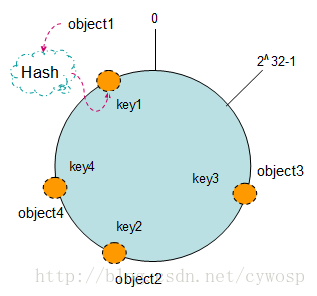
2. 把对象映射到Hash空间
现在我们将object1、object2、object3、object4四个对象通过特定的Hash函数计算出对应的key值,然后散列到Hash环上。如下图:
Hash(object1) = key1;
Hash(object2) = key2;
Hash(object3) = key3;
Hash(object4) = key4;
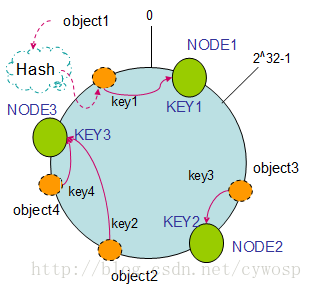
3. 把cache映射到Hash空间
Consistent hashing 的基本思想就是将对象和 cache 都映射到同一个 hash 数值空间中,并且使用相同的 hash算法。(一般情况下对机器的hash计算是采用机器的IP或者机器唯一的别名作为输入值),然后以顺时针的方向计算,将所有对象存储到离自己最近的机器中。
假设现在有NODE1,NODE2,NODE3三台机器,通过Hash算法得到对应的KEY值,映射到环中,其示意图如下:
Hash(NODE1) = KEY1;
Hash(NODE2) = KEY2;
Hash(NODE3) = KEY3;
4. 把对象映射到cache
通过上图可以看出对象与机器处于同一哈希空间中,这样按顺时针转动object1存储到了NODE1中,object3存储到了NODE2中,object2、object4存储到了NODE3中。在这样的部署环境中,hash环是不会变更的,因此,通过算出对象的hash值就能快速的定位到对应的机器中,这样就能找到对象真正的存储位置了。
5. 考察cache的变动
普通hash求余算法最为不妥的地方就是在有机器的添加或者删除之后会照成大量的对象存储位置失效,这样就大大的不满足单调性了。下面来分析一下一致性哈希算法是如何处理的。
5.1 Cache移除
以上面的分布为例,如果NODE2出现故障被删除了,那么按照顺时针迁移的方法,object3将会被迁移到NODE3中,这样仅仅是object3的映射位置发生了变化,其它的对象没有任何的改动。如下图:
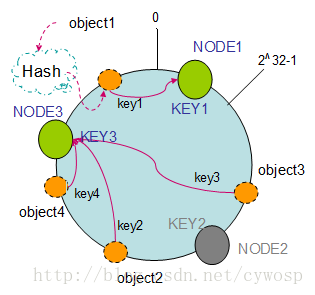
5.1 Cache增加
如果往集群中添加一个新的节点NODE4,通过对应的哈希算法得到KEY4,并映射到环中。通过按顺时针迁移的规则,那么object2被迁移到了NODE4中,其它对象还保持这原有的存储位置。如下图:
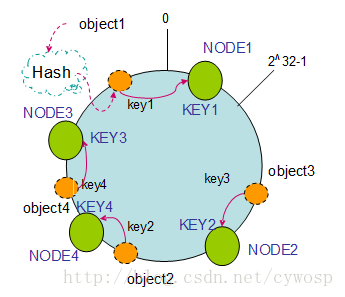
通过对节点的添加和删除的分析,一致性哈希算法在保持了单调性的同时,还是数据的迁移达到了最小,这样的算法对分布式集群来说是非常合适的,避免了大量数据迁移,减小了服务器的的压力。
平衡性与虚拟节点
根据上面的图解分析,一致性哈希算法满足了单调性和负载均衡的特性以及一般hash算法的分散性,但这还并不能当做其被广泛应用的原由,因为还缺少了平衡性。
如上面只部署了NODE1和NODE3的情况(NODE2被删除的图),object1存储到了NODE1中,而object2、object3、object4都存储到了NODE3中,这样就照成了非常不平衡的状态。
引入虚拟节点的好处:
- 在memcached服务器较少的情况下,很难平均的分布到hash环上,这样就会造成负载不均衡。引入虚拟化节点,可以解决这个问题
- 当一台memcached宕机时,其原先所承受的压力全部给了其下一个节点,为了将其原先所承受的压力尽可能的分布给所有剩余的memcached节点,引入虚拟化节点可以达到这个目的
- 当新添加了一台memcached服务器server1时,server1只会缓解其中的一台服务器(即server1插入环后,server1的下一个节点)的压力,为了可以让server1尽可能的缓解所有的memcached服务器的压力,引入虚拟节点可以达到这个目的
一致性哈希算法中,为了尽可能的满足平衡性,其引入了虚拟节点。
“虚拟节点”( virtual node )是实际节点(机器)在 hash 空间的复制品( replica ),一实际个节点(机器)对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以hash值排列。
以上面只部署了NODE1和NODE3的情况(NODE2被删除的图)为例,之前的对象在机器上的分布很不均衡,现在我们以2个副本(复制个数)为例,这样整个hash环中就存在了4个虚拟节点,最后对象映射的关系图如下:
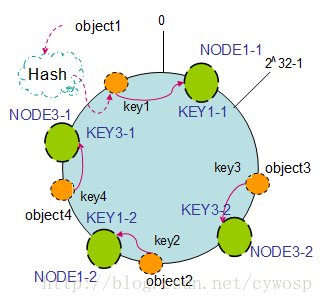
根据上图可知对象的映射关系:object1->NODE1-1,object2->NODE1-2,object3->NODE3-2,object4->NODE3-1。通过虚拟节点的引入,对象的分布就比较均衡了。
在实际操作中,正真的对象查询是如何工作的呢?对象从hash到虚拟节点到实际节点的转换如下图:
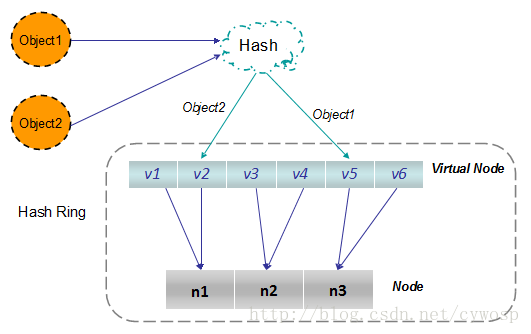
“虚拟节点”的hash计算可以采用对应节点的IP地址加数字后缀的方式。例如假设NODE1的IP地址为192.168.1.100。引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash(“192.168.1.100”);
引入“虚拟节点”后,计算“虚拟节”点NODE1-1和NODE1-2的hash值:
Hash(“192.168.1.100#1”); // NODE1-1
Hash(“192.168.1.100#2”); // NODE1-2
Python 版代码演示
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from zlib import crc32
import memcache
class HashConsistency(object):
def __init__(self, nodes=None, replicas=5):
# 虚拟节点与真实节点对应关系
self.nodes_map = []
# 真实节点与虚拟节点的字典映射
self.nodes_replicas = {}
# 真实节点
self.nodes = nodes
# 每个真实节点创建的虚拟节点的个数
self.replicas = replicas
if self.nodes:
for node in self.nodes:
self._add_nodes_map(node)
self._sort_nodes()
def get_node(self, key):
"""
根据KEY值的hash值,返回对应的节点
算法是:返回最早比key_hash大的节点
"""
key_hash = abs(crc32(key))
#print '(%s' % key_hash
for node in self.nodes_map:
if key_hash > node[0]:
continue
return node
return None
def add_node(self, node):
# 添加节点
self._add_nodes_map(node)
self._sort_nodes()
def remove_node(self, node):
# 删除节点
if node not in self.nodes_replicas.keys():
pass
discard_rep_nodes = self.nodes_replicas[node]
self.nodes_map = filter(lambda x: x[0] not in discard_rep_nodes, self.nodes_map)
def _add_nodes_map(self, node):
# 增加虚拟节点到nodes_map列表
nodes_reps = []
for i in xrange(self.replicas):
rep_node = '%s_%d' % (node, i)
node_hash = abs(crc32(rep_node))
self.nodes_map.append((node_hash, node))
nodes_reps.append(node_hash)
# 真实节点与虚拟节点的字典映射
self.nodes_replicas[node] = nodes_reps
def _sort_nodes(self):
# 按顺序排列虚拟节点
self.nodes_map = sorted(self.nodes_map, key=lambda x:x[0])
""" 测试 """
memcache_servers = [
'127.0.0.1:7001',
'127.0.0.1:7002',
'127.0.0.1:7003',
'127.0.0.1:7004',
]
h = HashConsistency(memcache_servers)
for k in h.nodes_map:
print k
mc_servers_dict = {}
for ms in memcache_servers:
mc = memcache.Client([ms], debug=0)
mc_servers_dict[ms] = mc
# 循环10此给memcache 添加key,这里使用了一致性hash,那么key将会根据hash值落点到对应的虚拟节点上
for i in xrange(10):
key = 'key_%s' % i
print key
server = h.get_node(key)[1]
mc = mc_servers_dict[server]
mc.set(key, i)
print 'SERVER :%s' % server
print mc
Java版演示代码 http://www.cnblogs.com/java-zhao/p/5223926.html
http://www.cnblogs.com/xrq730/p/5186728.html
GO-BACK UP-LEVEL TOP